![]()
Contenidos
Tema anterior
ILI-285 Computación Científica I 2012
Próximo tema
Clase 2: Espacios Vectoriales y Multiplicación de Matrices
![]()
ILI-285 Computación Científica I 2012
Clase 2: Espacios Vectoriales y Multiplicación de Matrices
Se refiere al conjunto de técnicas usadas para resolver problemas en ciencia e ingeniería. Es difícil delimitar el ámbito de lo que se llama Computación Científica pero se aceptará como definición:
Computación Científica es la colección de herramientas, técnicas y teorías requeridas para resolver modelos matemáticos en ciencia e ingeniería usando un computador [Golub93].
La mayoría de estas herramientas, técnicas y teorías originalmente desarrolladas en matemáticas, fueron desarrolladas antes de la aparición de los computadores. A este conjunto de teorías y técnicas matemáticas se les llama Análisis Numérico y constituye una parte importante de la Computación Científica.
Sin embargo, el desarrollo de los computadores, hizo que muchos de los métodos numéricos pensados para resolver problemas a mano fueran optimizados para su uso con computadores o abandonados definitivamente. Ahora debían considerarse factores como:
- Lenguajes de programación
- Sistemas operativos
- Manejo de grandes cantidades de datos
- Correctitud de los programas
Por lo tanto, la Computación Científica incluye teorías y herramientas del Análisis Numérico teniendo en consideración los aspectos técnicos del uso de computadores.
Text mining (o minería de texto) tiene relación con la obtención de información relevante a partir de textos. Uno de los primeros enfoques propuestos en text mining fue el Vector Space Model (VSM), planteado por Gerard Salton [Salton]. El método consiste en:
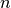 documentos de texto con vectores de documentos
documentos de texto con vectores de documentos 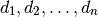
![$A_{m\times n}=[d_{1}| d_{2}| \ldots |d_{n}]$](_images/math/0fcdbcb81e06a414f9bbd5a928142c8d4e16cfbe.png) :
: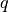
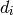 más cercano al vector .
más cercano al vector .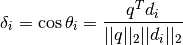
Por ejemplo, si se tienen los siguientes términos:
y los siguientes documentos:
expresado en forma matricial se tiene:
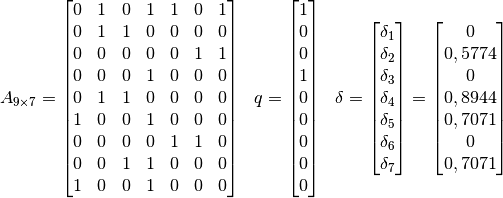
El vector representa la query que busca al documento que tenga los
términos Bab(y, ies, y’s) y Health.
Se quiere encontrar el vector más cercano a
, lo que implica que el ángulo entre ambos vectores debe ser (idealmente)
igual a 0, y 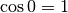 , por lo tanto, el documento
, por lo tanto, el documento 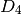 es el más
cercano.
es el más
cercano.
El VSM es un modelo muy simple que permite calcular un grado de similaridad entre documentos y queries, pero tiene desventajas, por ejemplo con los sinónimos y la polisemia (cuando una palabra tiene varios significados, ej. gata), por lo que se han desarrollado nuevos modelos, entre ellos el Latent Semantic Indexing, el cual utiliza SVD para la identificación de patrones y relaciones entre los términos de los documentos [SEO_Blog].
La computación científica muchas aplicaciones en el procesamiento de imágenes. Una de ellas es el uso directo de la descomposición de valor singular (SVD por sus siglas en inglés) para la compresión de imágenes. El procedimiento es muy simple. Consiste en el cálculo de la descomposición SVD de la imagen y luego utilizar sólo los valores singulares más significativos para reconstruirla usando las matrices obtenidas truncadas.
En la siguiente figura (Porsche Boxter 2012) se muestran las imágenes obtenidas usando diferentes porcentajes de los valores singulares.

El siguiente código en Python muestra el procedimiento realizado para obtener las imágenes:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | from pylab import *
from scipy.linalg import *
lala
# Lectura de la imagen
A = imread("Porsche_Boxster_2012.jpg")[:,:,0]
gray()
compress = numpy.zeros(A.shape)
U,S,V=svd(A)
s = numpy.zeros(A.shape)
s[:len(S),:len(S)] = numpy.diag(S)
rate = 0.01
N = int(rate * len(S))
compress = numpy.dot(numpy.dot(U[:,:N],s[:N,:N]),V[:N,:])
imshow(compress, origin='lower')
show()
|
En la línea 10 se realiza el cálculo de la descomposición SVD y en la línea 16 se obtiene la imagen usando las matrices truncadas de la descomposición. Las líneas 18 y 19 muestran la imagen resultante.
En el año 1990, durante la Guerra del Golfo, los misiles Patriot se hicieron populares y se usaron principalmente para interceptar misiles balísticos. Después de diversas pruebas se probó su correcto funcionamiento, pero ocurrió un gran error que costó la vida de 28 soldados norteamericanos.

El misil estaba diseñado para operar solo unas cuantas horas.
La velocidad del misil que se quería interceptar (misil objetivo), era
representada por un número de punto flotante, pero el tiempo del reloj interno del sistema se representaba por un entero, correspondiente a décimas de segundo.
Antes de usar aquel tiempo, el número entero era multiplicado por una
aproximación numérica de 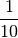 (para transformar las décimas de segundos en segundos),
representada en 24 bits.
(para transformar las décimas de segundos en segundos),
representada en 24 bits.
En particular el valor tiene una expansión binaria infinita, y
fue truncado a los 24 bits. Recordemos:
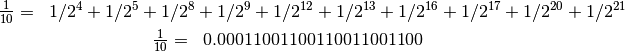
El pequeño error de truncamiento,  , multiplicado por
un gran número, produjo un gran error.
, multiplicado por
un gran número, produjo un gran error.
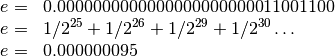
El sistema del misil Patriot estuvo corriendo 100 horas lo que produjo un error
de ![0.34[s]](_images/math/4fee8933a3c7c6840103b454b1bb4507dda9b781.png) , es decir, el reloj del sistema se atrasó aproximadamente un
tercio de segundo:
, es decir, el reloj del sistema se atrasó aproximadamente un
tercio de segundo:
![0.000000095 \times 100 \times 60 \times 60 \times 10=0.34 \text{ [seg]}](_images/math/93d1c1d5e684c700d32b1edc80a2b3092ca05eba.png)
La velocidad del misil objetivo era de 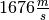 ,
por lo tanto:
,
por lo tanto:
![1676\frac{m}{s} \times 0.34[s] = 569.84[m]](_images/math/209f809b492e9359e6ec7cdb1934a97c53e09ea7.png)
provocando un error de posición de casi ![600[m]](_images/math/f7e23407552e990573035e49455e3d9ac19d050a.png) , lo que provocó que el radar del misil Patriot buscara en un lugar en que el misil objetivo ya no estaba, asumiendo que se trataba de una falsa alarma [Arnold].
, lo que provocó que el radar del misil Patriot buscara en un lugar en que el misil objetivo ya no estaba, asumiendo que se trataba de una falsa alarma [Arnold].
Este ejemplo, es una aplicación concreta de los conceptos de aritmética de punto flotante (floating point arithmetic) y estabilidad de algoritmos (en este caso, un algoritmo inestable!).
Las redes neuronales artificiales (ANN por sus siglas en inglés) han sido ampliamente utilizadas para el modelamiento de diversos problemas de la ciencia. Las ANN están formadas por un grupo de neuronas conectadas simulando el proceso de synapsis. En la figura se muestra un tipo de ANN, la red feedforward (FFN) la cual cuenta con tres capas: entrada, escondida y salida.

Luego de un período de entrenamiento, los pesos de las conexiones entre las neuronas de la red quedan determinados, y es posible analizar el comportamiento de la red ante nuevas entradas.
Este problema del área de Máquinas de aprendizaje puede ser representado matricialmente y por lo tanto utilizar todas las herramientas de la computación científica.
Las conexiones entre la capa de entrada y la capa escondida pueden ser representadas por la siguiente matriz:
![W_{h \times {n}} =
\left[
\begin{array}{ccc}
w_{1, 1} & \cdots & w_{1, n} \\
\vdots & \ddots & \vdots \\
w_{h, 1} & \cdots & w_{h, n}
\end{array}
\right],](_images/math/69ef781def8a61a341d6822cd853a34367fbab22.png)
donde 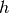 es el número de neuronas en la capa escondida y
es el número de neuronas en la capa escondida y 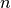 el número de entradas.
De la misma manera, las conexiones entre la capa escondida y la salida pueden ser representadas por el siguiente vector:
el número de entradas.
De la misma manera, las conexiones entre la capa escondida y la salida pueden ser representadas por el siguiente vector:
![\Delta_{1 \times h} =
\left[
\begin{array}{ccc}
\delta_{1,1} & \cdots & \delta_{1,h}
\end{array}
\right]](_images/math/5cfd96d6980979fb00132b887045e75a834dea82.png)
Debido a esta representación, el cálculo de la salida de la red se simplifica y queda reducida sólo a multiplicaciones simples.
| [Golub93] | Gene H. Golub, James M. Ortega. Scientific Computing: An Introduction with Parallel Computing. Academic Press, 1993. |
| [Arnold] | http://www.ima.umn.edu/~arnold/disasters/patriot.html |
| [Salton] | Carl D. Meyer. Proffessor of Mathematics, NC State University. Nonnegative Matrix Factorization in Text Mining. http://meyer.math.ncsu.edu/Meyer/Talks/SIAMSEAS_NMF.pdf |
| [SEO_Blog] | What is Latent Semantic Indexing (LSI)? http://www.seo-blog.com/latent-semantic-indexing-lsi-explained.php |